Jonathan Pool
Last revised: 25 November 02012
PanLex is a lexical database supporting the translation of single-word and multi-word lexemic expressions (the kinds of expressions that can be found in dictionaries and similar reference works) among all language varieties. PanLex editors consult thousands of sources to discover expression translations. This editorial work is complicated by the sources’ diverse structures, conceptualizations, reliabilities, publication statuses, and other properties. This technical report discusses the derivation of PanLex data from their sources.
The data in the PanLex database consist of factual assertions by editors, who in turn generally base each assertion on some authoritative work, such as a bilingual dictionary. The editor (or group of editors) and the consulted source, together, are treated as the “approver” of any factual assertion. The editor documents the approver by cataloguing its source in the database. The catalogue record includes an identifying label and an editorial quality estimate, and it may also include a URL, ISBN, author(s), title, publisher, year of publication, license type, permission statement, name of licensor, email address for licensing correspondence, language varieties covered, and file format(s).
Sources of PanLex data often have “entries” as their units. Such an entry might assert that “money” in English, “dinero” in Spanish, and “tomi” in Yaqui are translations of each other. If so, the editor interprets it as a set of factual assertions:
Statements 5–7 are “denotations” (each assigning 1 meaning to 1 expression). The editor’s work includes (1) checking whether each of these expressions is already in the PanLex database, (2) adding any that aren’t there yet, (3) adding a meaning to the database with a new unique identifier (represented by “m” above), (4) associating that meaning with the source, and (5) adding the 3 denotations to the database.
Every meaning in the database is ascribed to a unique approver. Consequently, every denotation can be ascribed to its meaning’s approver. Of course, multiple approvers may assert that “money” and “dinero” share a meaning, but an editor, in creating denotations, does not assign existing meanings of other approvers to expressions. Any inferences that distinct approvers’ meanings are “really” the same is left for users of the database to draw.
By contrast, if “money” in English is already in the database, it is re-used for any new denotation that assigns a meaning to that expression. PanLex naïvely defines an expression by its language variety and its lemmatic text. Thus, “bear” in English is a single PanLex expression, not several.
PanLex textual data are encoded in compliance with the Unicode Standard. All text added to the PanLex database must consist of Unicode characters and be serialized with the UTF-8 encoding form. The Unicode standard was first published in 1991 and has become increasingly universal since then, but many digital sources are not Unicode-compliant. They use various open and proprietary character encodings, some defined by standards and others inferrable by inspection of the glyphs in the fonts that they rely on. In such cases, editors convert strings to Unicode and UTF-8. This may require the construction of mappings from legacy fonts to Unicode codepoints.
Even when sources represent text with Unicode characters, sources differ in how they represent complex characters, such as characters with diacritical marks. Some sources represent these with sequences of characters to be composed (e.g., “o” with “ ́” superimposed on it), and others represent them with precomposed characters (e.g., the single character “ó”). Both such representations are Unicode-compliant. PanLex enforces Unicode Normalization Form NFC on its text data: Any precomposed characters that exist in Unicode are substituted for the equivalent sequences of base letters plus diacritical marks.
Some punctuation and punctuation-like characters in expressions are poorly standardized in practice, and without editorial intervention this would lead to multiple versions of the same expressions, treated as if they were distinct. Apostrophe-like characters are among these. We encounter one or more of the apostrophe (U+0027), the modifier letter apostrophe (U+02BC), the right single quotation mark (U+2019), the modifier letter turned comma (U+02BB), and the Hebrew punctuation geresh (U+05F3) used in identical contexts. We likewise find various sources using the combining comma below (U+0326) and the combining cedilla (U+0327) for the same purpose (one source may write “București” in Romanian, with a combining comma, while another writes “Bucureşti”, with a cedilla). PanLex editors have the discretion to standardize such characters, so that expressions from diverse sources are treated as identical when they are substantively identical.
In languages with letter case, some sources routinely capitalize the initial letters of all headwords as a matter of style, thus introducing more ambiguity than the language normally allows (e.g., Polish/polish, Turkey/turkey, March/march). In some cases, authorities disagree on letter-case standards, such as on whether bird names should be capitalized. Editors exercise discretion to standardize letter case.
Some sources mark some or all meanings, or individual translated expressions, with grammatical properties, such as “noun” or “v.t.” Editors can assign word-class values, chosen from PanLex’s fixed set of word classes, to denotations. PanLex word classes are properties of denotations and not of meanings. Thus, word-class-heterogeneous translations, in which, for example, an adjective in one language shares a meaning with a noun in another language, are possible. Editors may also record additional and more complex information (valence, gender, class, register, etc.) as arbitrary “metadata” (each with an attribute and a value) attached to denotations.
Lexicographic conventions define the lemmatic (i.e. dictionary, or citation) forms of expressions, and different sources usually follow these conventions. But there are disagreements, deviations, and internal inconsistencies, and for most languages the only written forms are those used by descriptive linguists documenting the languages. Variations in letter case were mentioned above. Sources also sometimes differ in which particles or affixes they include in lemmas. For example, some sources indicate that an English expression is a verb by prepending it with “to”. Sources treat prefixes and hyphens differently in the representation of lemmas in Bantu languages. Library subject authorities and thesauri, unlike dictionaries, often pluralize some nouns that describe classes of things. Sources vary in how they represent complex phrasal lexemes (such as “the more the …”, “be up to …”, or “beg someone’s pardon”), and in whether they include argument specifiers (e.g., “free from”, “free to”). PanLex editors apply judgment in deciding whether to represent expressions as sources represent them or to alter those forms in the interest of standardization.
Sources often are directional, while PanLex is nondirectional. In other words, sources of lexical translations often treat one language as the source language and the other languages as target languages. PanLex, in contrast, is a network of expressions and meanings that can be traversed in any direction. This difference complicates the acquisition of knowledge whenever a source gives a complex translation for an expression. A PanLex editor must then judge whether to treat that translation as an expression or as a definition, and, if the latter, whether also to derive an expression from it. If an expression is, for example, translated into English as “be or stay idle”, the editor might choose to treat that translation as a definition. The editor might then derive from it “be idle” and “stay idle” as expressions; or decide that it is more appropriate to designate “idle” as the sole expression (as either a verb or an adjective); or find a synonymous verb, such as “loaf” or “relax”, and use it as the (or an additional) expression, even if that that word does not appear in the consulted work.
Whenever a source provides more than one translation for an expression into the same language, the question arises whether those translations are intended to be synonyms or, instead, representations of distinct meanings of the translated expression. The editor must make this determination in order to decide whether to describe all the translations as sharing a single meaning with the translated expression or to describe each as sharing a distinct meaning. Sometimes the answer is obvious, but not always. Kinship, color, body-part, and other concepts often elicit dissimilar judgments as to meaning identity, depending on one’s linguistic experience. An editor can choose to defer to a source, but some sources make their intentions unclear.
Editors, when they check for existing expressions and add new ones to the database, identify each expression’s language variety. Generally that determination is not purely objective; it requires judgment. If in the editor’s judgment the expression is not in a variety that already exists in the database, the editor adds another variety. PanLex requires the editor to specify for that new variety (1) an alpha-3 ISO 639-2, -3, or -5 language code (there are about 8,000 to choose among) and (2) a label, which is normally an autonym, i.e. a name of the variety in the variety itself. PanLex registers this variety and assigns a serial integer to it as a variety code, to distinguish it from other varieties with the same language code.
Most generally recognized languages initially have only 1 variety in PanLex, but as editors examine more sources they often judge it appropriate to treat a source as documenting a distinct variety of a language. Varieties can be distinguished on the basis of scripts, regional dialects, literary standards, artificial codes, and other differences.
Most compendia of lexical translations have semi-regular structures. They use paragraph breaks, punctuation, typefaces, and other format elements with partial consistency. Thus, they leave room for editorial interpretation. If a headword looks like “ban tuf” and later in the entry “~ lon” appears, does this stand for “ban tuf lon” or “ban lon”? If an expression is translated as “ladder, pilot”, does it have the two meanings “pilot” and “ladder”, or does it have the single meaning “pilot ladder”? If the translation is shown as “drug abuse or addiction”, is the intent to provide a single definition or two expressions, and, if the latter, is the second expression “addiction” or “drug addiction”? One source translates a word into English as “bundle, bundle of long, stiff objects”; a human editor who knows English can infer that this is a sequence of 2, not 3, translations, and that the first comma delimits them, but writing a program that correctly parses all such strings is not straightforward.
In vivo validation (using the existing content of PanLex to validate new additions) cannot reliably resolve all such structural ambiguities. One consulted resource translates one lexeme into English as “gopher, pocket” and another lexeme as “meat, flesh”. All four English words are common, and “pocket gopher” and “flesh meat” are also attested lexemes, but contextual editorial inspection suggests that the compiler used the comma with two different purposes: inversion for “pocket gopher” and synonymous alternation for “meat, flesh”.
Given all of the interpretive and standardizing discretion described above, it should be clear that automating the consultation of lexical resources is not entirely straightforward. Insofar as it is practical, however, PanLex editors do this. They re-use existing general-purpose tools, re-use tools that other editors have developed for PanLex, and develop new tools. The usual practice is to perform minor editorial corrections, if any, on the original files and thereafter to use stored subroutines from the PanLex script library for any remaining extraction and conversion of data. All such edited versions and subroutines are archived along with the original files, so that an editor could reproduce the derivation of content later, modify the subroutine logic or parameters to improve the derivation, or apply the same procedure to a new version of the original file.
As of now, all custom subroutines for content derivation have been written in Perl.
Tools developed by others that have been used in PanLex content derivation include recoding utilities and mapping tables published by SIL International and others, and the “pdftotext” utility that is part of the Xpdf library.
Other tools may deserve incorporation into the PanLex toolset. An example of a possibly useful library for the manipulation of text files is the Apache Tika content-analysis toolkit. Several tool libraries for converting page images to text files, such as Ocropus, Tesseract, the I.R.I.S. iDRS SDK, and the Abbyy FineReader Engine SDKs, may merit testing and training for PanLex use.
For all the reasons given above, data in PanLex are not, and are not intended to be, replicas of data in the consulted works. An assertion in PanLex is best understood as a statement of this form: “The editors of the data based on source s assert, in reliance on that source, that meaning m is shared by expressions e₁, e₂, … eₙ.” The editor who added or later edited the data may have made additions, subtractions, and modifications. Data of types not provided for in PanLex, such as usage examples and nonlemmatic inflections, may have been omitted. Because of the differences between sources and the PanLex data based on them, PanLex isn’t generally a substitute for its sources, nor is it safe to quote a PanLex translation as if it had been quoted from its source. Users of PanLex can follow source references and consult sources directly for more information and for validation of PanLex data.
Lexicographic sources usually cite, and rely on, other lexicographic sources. PanLex editors generally document the source of each denotation, but don’t try to document the subsidiary sources on which the immediately consulted source relies. This level of attribution may fall short of full compliance with the EMELD and the Bird and Simons concepts of best practices in language documentation. Bird and Simons recommend (p. 19) that language documenters provide “complete citations for all language resources used”. How to define “complete” in the context of PanLex is not obvious.
PanLex began as a research project on computational lexical translation inference. It is evolving into a resource to support the translation of any lemmatic expression in any language into any other language. The vast majority of such translations are not attested. The only practical way to get them is to rely on automated inference from attested translations. When an algorithm produces a hypothetical translation, it may have taken account of translations attested by hundreds of sources. In such cases, the notion of the source(s) of a translation based on PanLex may be difficult to operationalize or intuit.
PanLex data are accessed through various interfaces, some designed by participants in the project and others designed by others. One can expect that the simplest interfaces, such as mobile interfaces for quick translations, may not offer access to all available information about sources. Users wanting that information may need to switch to a more complete interface.
The PanLex project aims to make its lexical translation data as accessible as possible to users of all kinds for their unrestricted use. This aim raises the question whether PanLex editors have the right to consult sources and populate PanLex with the editors’ interpretations of the sources’ factual assertions. This is a complex question, on which knowledgeable persons have differing opinions.
Sources’ creators and publishers differ in the ownership claims they make. Some assert that particular languages are the property of their native speakers or traditional communities and may not be used by others without permission. Others don’t make claims for language ownership, but do claim ownership over lexicographic works documenting languages. These claimants state that their permission is required before anybody uses the works for commercial purposes, or creates derivative works from them, or uses them for anything other than educational purposes. Still others don’t claim to restrict the use of their works, but state only a requirement that the works be properly acknowledged and/or referenced. Finally, there are some who disclaim any restrictions on the use, modification, and even acknowledgement of their works. Some claims are stated as legal ones, others as moral ones, and others vaguely.
Until now, no ownership claims have been made objecting to the uses of sources in the PanLex project. The ideal of open access to linguistic knowledge appears to be growing in popularity, and many authors of PanLex sources appear to appreciate any use of their work that makes the languages they have documented more known and more viable. Nonetheless, the project may in the future receive claims against the uses made by PanLex of particular sources. In that event, the project could omit or remove translations based on those sources. Alternatively, such claims could be questioned in at least the United States on the basis of a fair-use analysis that takes into consideration the transformative features provided by PanLex, benefiting the user public, compared with what the public can do with the individual sources.
The 1996 Turkmen–English Dictionary of Garrett et al. illustrates some of the editorial issues discussed above. Consider the four entries from that publication shown below. Based on them, an editor might produce the PanLex full-text file shown next to it, for upload into the database.
|
➡ | : 2 tuk-000 eng-000 ex garamyk ex chickenpox df eng-000 a kind of plant ex garamyk ex plant ex garanjaklamak ex look around wc verb ex garantja ex scarecrow ex garaňky ex dark ex unlit ex garaňky ex darkness |
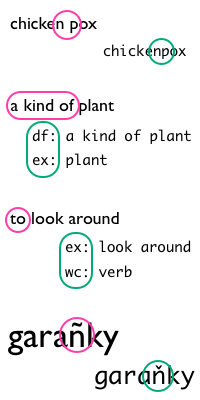
This file exhibits the following decisions made by the hypothetical (but typical) editor:
A different editor might have made some decisions differently, such as:
One of the larger sources of data in PanLex, labeled “mul:Usher”, is “Lexicon Enhancement via the GOLD Ontology Wordlists”, by Timothy Usher and Paul Whitehouse.
Source. The source was produced by the LEGO (Lexicon Enhancement via the GOLD Ontology) project. It is a revision of about 2,700 word lists developed by numerous authors and integrated into a set of tables with associated metadata and many corrections by Paul Whitehouse and Timothy Usher. Those tables pair lexemes with about 2,300 concepts that span the word lists, making it possible to translate words among about 1,700 language varieties. Until Whitehouse and Usher converted the original lists into integrated tables, the relative inaccessibility and format diversity of the lists would have made their large-scale use implausible. And, until the LEGO project began modernizing these data, they were still unpublished and, if one obtained a copy, not amenable to automated examination. Using them in a contemporary computational environment would have required converting them from dozens of separate Microsoft Excel workbooks, recoding the texts from the now-archaic IPA Kiel font-based character encoding to Unicode, identifying the language varieties with a widely adopted standard such as ISO 639, and parsing the table cells to extract their various data and metadata into a systematic structure. The LEGO project aims to achieve these purposes and more: It also seeks to integrate the metadata into the General Ontology for Linguistic Description (GOLD) and make this set of data interoperable with data from other sources. That effort, when completed, will convert the vision motivating the massive efforts of Whitehouse and Usher into reality.
When the PanLex project decided to proceed with the use of these LEGO data, the LEGO project was in the midst of modernizing them. It had produced a set of Unicode-encoded XML files out of the pre-Unicode Excel workbooks but had not yet completed the language identification or the cell parsing. The PanLex use thus involved some complexity that might have been avoided with a future version of the LEGO data. By not waiting, PanLex obtained an immediate infusion of about 420,000 expressions, mostly in “low-density” (i.e. poorly documented) languages, paired with meanings. This decreased greatly the inequality in the distribution of PanLex’s language coverage. The total count of language varieties with data in PanLex increased from 1,630 to 3,217. The count of language varieties with at least 200 PanLex expressions increased from 758 to 1,528. And the count of language varieties with at least 600 PanLex expressions increased from 458 to 568.
The source consisted of version 5 of the LEGO XML files, dated 20 June 2010, and version 3 of the LEGO concept table, dated 21 January 2011. This concept table was found superior for this work to two alternatives: version 4 of the concept table, because the French, Spanish, and German strings were miscoded in that version; and the LEGO “concepticon”, because it omitted French, Spanish, and German translations, English definitions, and English-lexeme word classes. The processing took place in February 2011.
The concept table was used as the source for denotations with expressions in English, French, Spanish, and German. The XML files were used as sources for denotations with expressions in all other language varieties. The two source files were integratable because they used the same set of numeric concept identifiers.
Character encoding. The text strings in the Usher worksheets were pre-Unicode (they used the proprietary IPA Kiel encoding), but the LEGO project made the text strings Unicode-compliant. In principle, therefore, the data required no further recoding for PanLex compatibility. However, Unicode compliance in reality was not total. Some English and German glosses were miscoded in the original Whitehouse tables and remained miscoded through both further processing stages. For example, in one location “thought” was represented as “thouVt” in a Whitehouse table and the resulting Usher worksheet and was converted to “thouɣt” in the LEGO XML text file. Likewise, “accompany” became “aččompaɲ” and “foot” became “fo:t”. It was necessary to detect and correct such incorrect encodings of glosses.
Compositional normalization. Textual LEGO data were almost entirely decomposed: Diacritical marks were represented as distinct characters from the base letters that they modified. The required conversion of decomposed characters to NFC characters was not difficult, because PanLex performs it automatically on all received data.
Punctuation. The LEGO data used two apostrophe-like characters apparently interchangeably: apostrophe (U+0027) and right single quotation mark (U+2019). The editor made the assumption that apostrophes in European languages are right single quotation marks (U+2019) and apostrophes in other languages are modifier letter apostrophes (U+02BC). The latter assumption is based on the fact that most non-European expressions in the LEGO data were represented in the International Phonetic Alphabet, in which the modifier letter apostrophe is a standard character (used for ejective consonants). Were orthographic forms prevalent in the data and their apostrophes not standardized, language-by-language standardization would have been more appropriate.
Word class. The concept table provided systematic word-class data for English, and these were used. Word-class data embedded in the XML files were sufficiently rare and inconsistent that no attempt was made to isolate and apply them.
Lemmatic forms. The concept table represented concepts in up to 4 European languages, but not entirely as expressions. For example, one concept was represented in English as “2 pl., poss.”, and this was editorially changed to “your”. Some concept-table items needed conversion into expressions plus definitions. For example, “young of animal” was converted to the expression “young” and the definition “young (of an animal)”.
Additional translations. In the LEGO XML files, each entry documented a single meaning, identified with its numeric index, so multiple translations in an entry (in “gold:formUnit” elements within distinct “lego:variant” elements) were treated as synonyms. However, some entries contained additional translations of a different type: glosses in English, German, or Dutch, which described more specific senses of the meaning or additional meanings of the entry’s head expression. Since those special or additional meanings were not covered by the general numerically indexed meaning list, each such gloss was treated as a translation of the head expression with a new meaning. About 28,000 such pairwise additional translations were identified.
Language varieties. It was necessary to make two language-identification decisions for each of the XML files: (1) What was the most appropriate ISO 639 code for the language variety that it covered, and (2) what variety code should be assigned to it? ISO 639 codes had been assigned to most of the XML files (represented as values of the “olac:code” attributes of the “dc:subject” elements), but 320 of them (12%) had only placeholder codes. Usher conducted further investigations and proposed (1) ISO 639 code assignments for almost all files not having them, (2) revisions to some already assigned codes because they were judged erroneous or the ISO 639-3 authority had made code changes, and (3) variety codes. The variety codes expressed Usher’s judgments on variety differentiation: Files judged to be different reports on the same variety were assigned the same variety code, and files judged to describe distinct varieties of a language were assigned distinct variety codes. Varieties already in PanLex were given their existing variety codes. Usher’s recommendations were adopted after further proofreading, research, consultations, and revisions. The decisions were documented in a map from numeric identifiers to language-variety identifiers.
Structural analysis. The LEGO lexeme representations (except in the European languages) were the values of “gold:formUnit” elements in the LEGO XML files. They were strings describing the phonetic or phonemic forms of lemmas and were usable as PanLex expressions. However, this generalization had many exceptions. Cells in the Whitehouse tables and the Usher worksheets, and “gold:formUnit” elements in the LEGO XML files, often included glosses (described above), inflectional series, and/or metadata about word class, grammatical number, orthography, etymology, illocutionary force, and other properties. An example of such an element is:
<gold:formUnit>gobe-na/gobe-yan/gobe-yʔ 'past/n.f. impfv/n.f. pfv.; ’tell lies’; ? '</gold:formUnit>
To deal with these exceptions, it was necessary to parse each “gold:formUnit” element to isolate its lemma from any other information. This parsing needed to cope with a variety of inconsistent delimiters and annotators, including spaces, tabs, ASCII apostrophes, right single quotation marks, colons, and question marks, some of which also were used as lexical characters. To the extent it was judged practical, this additional information was recorded appropriately.
Additional synonymous translations were not all correctly formatted in the LEGO XML files. If in the original tables the synonyms were separated with commas, they were split up as described above. But, if the original delimiters were tildes, the lists were not split. Thus, it was necessary to detect lists of alternate expressions embedded in “gold:formUnit” elements and split them into distinct expressions. In such cases any attached metadata were arbitrarily assumed to apply to all of the alternate expressions.
Glosses appended to expressions, described above, were in some cases incomplete. For example, a meaning translated into English as “belly” was also given the English gloss “my”, presumably not because the same expression meant “my” but because the expression really meant “my belly”. Thus, “gold:formUnit” values needed to be checked for incomplete translations. No rules were found to handle all the gloss-format inconsistencies, so as a last resort additional glosses in the European languages were subjected to “in vivo” validation: Glosses not matching existing well-attested PanLex expressions were excluded. The idea was this: This source covered about 2,300 main meanings, so one could expect that translations into high-density languages such as English and German would already be found in PanLex. If not, the most likely reason was a format or parsing error, not a rare expression.
Conversely, some items formatted as additional translations in the LEGO XML files were found to be something else. These included remarks such as “see below”. In one entry a meaning was represented as expressed by 7 alternate lexemes in the Wiradhuri language, but only 1 of these was in fact in that language: “barama-l”. The others, represented as being in Wiradhuri, were actually in English: “fetch”, “hold”, “take”, “carry”, “bring”, and “give”. In the Usher worksheet, the Wiradhuri lexeme and its additional translations were stored in a single cell: “barama-l 'get, carry, fetch, bring, give, take, hold'”. The LEGO conversion algorithm had apparently assumed as a first approximation that commas were the highest-precedence delimiters in the cells and that these delimiters invariably delimited alternate source lexemes. So, it was necessary to detect European-language glosses masquerading as lexemes in the file’s language variety, and to reclassify them. This correction work made use of typical patterns and involved matching all purported non-European lexemes in the XML files against a list of English expressions. Neither of these methods was straightforward, because there was no pattern perfectly correlating with errors of this kind and many expressions in the non-European languages were, by coincidence, formally identical to English expressions. Another worksheet-to-XML error that needed correction was the nonremoval of brackets from split lemma lists. For example, the cell “[ngeining, ngeinth]” had been transformed into 3 XML elements: “ngeining”, “ngeinth]”, and “[ngeining”.
In the concept table, format inconsistencies required editorial correction. The German expression “Widder oder Schafbock” needed conversion into two expressions, “Widder” and “Schafbock”. Inconsistent delimitation needed to be checked: “ashes, cool”, “burn, intr”, and “peak, summit” were notationally identical, but their commas performed three different functions.
Duplicate exclusion. With about 2,700 XML files covering about 1,700 language varieties, there were varieties with multiple files, due to the same or different researchers reporting on the same variety. It was thus possible for multiple files to assign the same meaning to the same expression. PanLex, however, treats the LEGO data as a single source and does not permit multiple identical denotations. So, any denotation encountered again after the first instance was disregarded, except that a provenance metadatum pointing to its file was added to the existing denotation, making it refer to all the XML files where it appeared. Any metadata attached to a duplicate denotation were also excluded. Usher’s notes described some of the XML files as duplicative of others. One file (1058: Gur.Dogon.njs.Swadesh_et_al.Usher06) was found identical to another (763: Dogonoid.Dogon_1.njs.Swadesh_et_al_UnspSrc.Usher06) except for 2 denotations in which their lemmas differed in transcription; those were merged into file 763 and file 1058 was removed. Other reported duplications were difficult to verify, so their duplicate removal was left to the above-described filtering routine.
Displacement correction. Error inspections led to a discovery that about 2% of the data were displaced by one row in the worksheets and correspondingly displaced in the XML files. This caused the affected lexemes to have been assigned incorrect meanings. This displacement was reversed where it had occurred.
Sources of sources. The LEGO data are based on about 2,700 subsidiary sources. Each source was identified in the XML files with a “lego:interop” element, whose value was up to 103 characters long, and in some cases more detailed bibliographic data were provided. For compactness, the subsidiary sources were given integer identifiers in the PanLex data, and these were attached to denotations as metadata (variable = “@”, value = numeric identifier). A map from numeric identifiers to “lego:interop” values and bibliographic data was made available. This map provides mostly fragmentary citations of the subsidiary sources, pending the completion of the source-documentation work by the LEGO project. This level of citation can reasonably be considered substandard, as discussed in a 2011 essay and a reply.
Conclusions. The LEGO project’s modernization and publication of the lexical data organized by Whitehouse and Usher are making their rich body of documentation on low-density languages available for the first time for open-access computational processing. PanLex is one of the early-stage beneficiaries of this work. Intercepting the data in mid-conversion may have been premature, in that it entailed additional cleaning. But this mid-course deployment may also reveal or clarify conversion issues that will be usefully addressed as the LEGO project proceeds.
The above-described corrections to language identification, embedded metadata, nonlemmatic inflections, alternate expressions, and metadata treated as lexemes involved tests and revisions consuming roughly two weeks of effort. They produced changes to about 15,000 “gold:formUnit” elements in the XML files, i.e. about 3% of the total. An impressionistic estimate is that about 95% of the errors that could have been detected by inspection (without familiarity with the original sources or knowledge of the non-European languages) were thereby corrected.
Some of the complexity arose from the yet-unfinished implementation of the LEGO project’s plans. The conversion of the worksheets’ proprietary encoding to Unicode clearly facilitated the use of the data by PanLex, but miscoded additional translations sprinkled throughout the XML files required corrective work. Likewise, it was obviously useful to PanLex that the LEGO project had split alternate lexemes into distinct XML elements. But errors in the parsing of worksheet cells, causing the mislabeling of thousands of English words as words in African, Asian, and Oceanic languages, had not yet been corrected.
It isn’t clear, however, that the completion of the work under way in the LEGO project would have eliminated the editorial complexities. There may also be design-based obstacles to interoperability between the two projects:
Interoperability involves not only the initial use of data, but also the updating of the data in the hands of the user when the source data are updated. This propagation of improvements could turn out to be straightforward or impractical, depending on how the updating process is managed. For example, if it was worth two person-weeks of investment for the PanLex project to make the LEGO data compatible, that is because of the major benefit to PanLex from having the data as compared with not having the data. If improvements to the LEGO data were to take the form of ad-hoc editorial corrections, and if assimilating the new version to PanLex were to require a repetition of the same two person-weeks of inspection-based efforts as before, the payoff this time would be only a fractional improvement in the data already in use. Thus, at this stage, incremental editorial improvements to the LEGO data are likely to remain unused by PanLex. The improvements that are likely to be used are those that eliminate the need for element-by-element inspection and permit fully programmatic conversion from one schema to the other. That implies extending the XML schema to reach inside the “gold:formUnit” elements, stopping only when the various facts stored within them have been fully and systematically analyzed.
![]()

{kind=link}